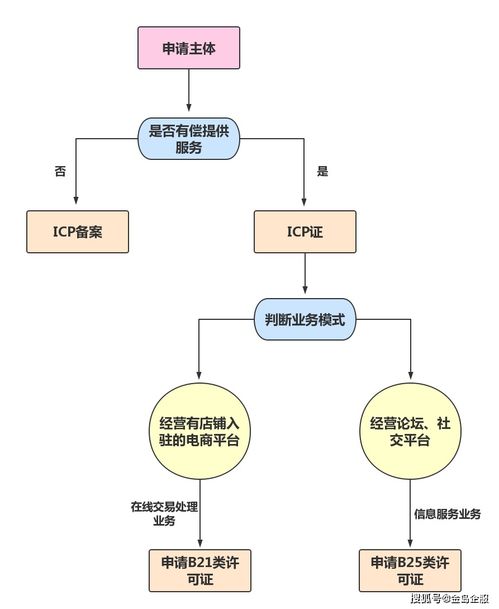
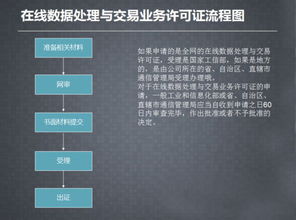
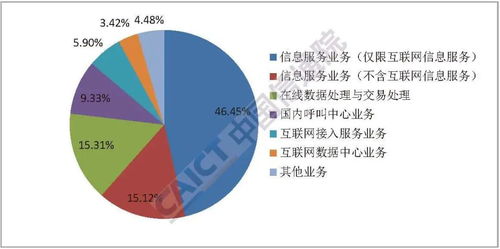
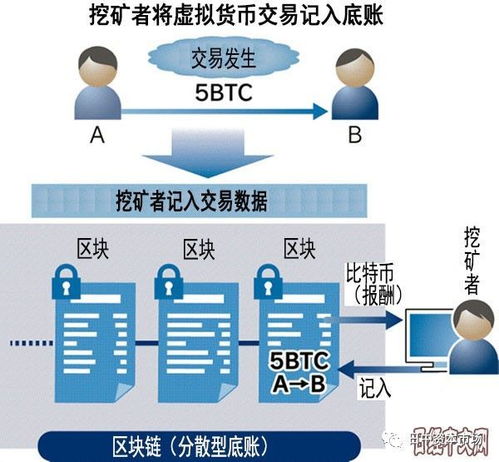
R語(yǔ)言學(xué)習(xí) 構(gòu)建Jupyter Lab工作環(huán)境與類別型數(shù)據(jù)處理在在線業(yè)務(wù)中的應(yīng)用
R語(yǔ)言作為統(tǒng)計(jì)分析和數(shù)據(jù)可視化的重要工具,在數(shù)據(jù)科學(xué)領(lǐng)域應(yīng)用廣泛。結(jié)合Jupyter Lab這一交互式開(kāi)發(fā)環(huán)境,用戶能更高效地進(jìn)行數(shù)據(jù)探索和建模。本文首先介紹如何在Jupyter Lab中配置R工作環(huán)境,接著總結(jié)類別型數(shù)據(jù)的處理方法,最后探討其在在線數(shù)據(jù)處理與交易處理業(yè)務(wù)中的實(shí)踐應(yīng)用。
一、Jupyter Lab中構(gòu)建R工作環(huán)境
在Jupyter Lab中使用R語(yǔ)言,需先安裝R語(yǔ)言環(huán)境及IRkernel包。步驟如下:
- 安裝R語(yǔ)言:從CRAN官網(wǎng)下載并安裝R。
- 安裝IRkernel:在R控制臺(tái)中運(yùn)行
install.packages('IRkernel'),然后執(zhí)行IRkernel::installspec()注冊(cè)內(nèi)核。 - 配置Jupyter Lab:確保已安裝Jupyter Lab,啟動(dòng)后即可選擇R內(nèi)核創(chuàng)建筆記本。這一環(huán)境支持代碼執(zhí)行、Markdown文檔編寫和實(shí)時(shí)可視化,便于數(shù)據(jù)分析和結(jié)果分享。
二、類別型數(shù)據(jù)處理方法總結(jié)
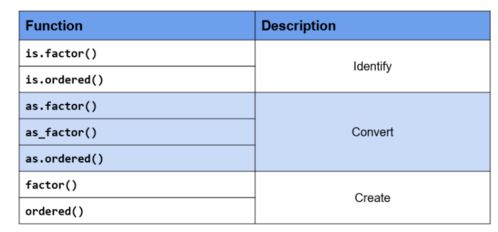
類別型數(shù)據(jù)(如性別、產(chǎn)品類別)在R中通常以因子(factor)形式處理,關(guān)鍵操作包括:
1. 創(chuàng)建與轉(zhuǎn)換:使用factor()函數(shù)將字符向量轉(zhuǎn)換為因子,可指定水平(levels)和標(biāo)簽(labels)。
2. 重編碼:通過(guò)recode()或ifelse()函數(shù)合并或修改類別,例如將多個(gè)類別歸并為更廣泛的組。
3. 啞變量生成:使用model.matrix()或dummyVars包創(chuàng)建啞變量,便于機(jī)器學(xué)習(xí)模型處理。
4. 排序與匯總:利用table()和summary()函數(shù)進(jìn)行頻數(shù)統(tǒng)計(jì),或使用dplyr包中的group_by()和summarise()進(jìn)行分組分析。
處理時(shí)需注意缺失值處理和類別不平衡問(wèn)題,以確保數(shù)據(jù)質(zhì)量。
三、在線數(shù)據(jù)處理與交易處理業(yè)務(wù)中的應(yīng)用
在在線業(yè)務(wù)場(chǎng)景中,如電商交易或金融平臺(tái),R語(yǔ)言結(jié)合Jupyter Lab可用于實(shí)時(shí)數(shù)據(jù)分析和決策支持:
1. 實(shí)時(shí)數(shù)據(jù)流處理:通過(guò)R包如shiny構(gòu)建交互式儀表板,監(jiān)控交易數(shù)據(jù)流并可視化關(guān)鍵指標(biāo)(如銷售額、用戶行為)。
2. 類別型數(shù)據(jù)應(yīng)用:例如,在用戶畫像分析中,處理用戶性別、地區(qū)等類別變量,以進(jìn)行細(xì)分市場(chǎng)推薦;在交易欺詐檢測(cè)中,將交易類型作為因子輸入模型,提高預(yù)測(cè)準(zhǔn)確率。
3. 自動(dòng)化報(bào)告:利用Jupyter Lab的筆記本功能,結(jié)合R腳本自動(dòng)生成交易報(bào)告,支持業(yè)務(wù)決策。
構(gòu)建高效的R工作環(huán)境并掌握類別型數(shù)據(jù)處理技巧,能顯著提升在線業(yè)務(wù)的處理效率和洞察力,推動(dòng)數(shù)據(jù)驅(qū)動(dòng)決策。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.newheight.com.cn/product/25.html
更新時(shí)間:2026-01-07 07:04:25